复杂网络学科大量的实证研究发现很多网络存在聚簇效应,比如常见的社交网络。正所谓人以群分,物以类聚。在数据挖掘中,有一个分支叫做社区检测(community detection),用于在复杂的网络中寻找无形的群聚关系。
任务描述
假如我们现在知道很多名微信用户,并且只知道这些微信用户之间的好友关系,即知道任意两个微信用户是否互为好友,就像下图一样。显然,在人与人的交往中难免产生一些小团体,就像现实生活中有同一个学校、同一个班级、同一个宿舍的学生会聚成不同层级的小团体,在微信中也存在群聊的功能。我们现在的任务是,试图只从多个微信用户之间的好友关系,去猜测这些用户的小团体,也就是把这些用户划分为一个一个不同的集合(假设一个用户只属于一个小团体)。
数据挖掘就是在一堆看似杂乱无章的数据中发现隐含的有价值的信息。在一般的机器学习中,聚类算法是在一些各自独立的向量上进行操作的,目的是将独立的向量划分成若干个聚簇。而社区检测可以看作是图论上的聚类算法:在一个拥有若干个节点和边的图中,将这些节点划分为若干个社区(聚簇)。不同的地方在于,机器学习中的经典聚类是用样本自身的属性来计算,通过每个个体自身的值来得到个体之间的相似性,从而划分为不同类。而社区检测则不关注每个点,而是只知道每个个体之间的关系,通过点与点之间的边来把整个图的点划分成若干个集合。
朴素思想
我们不妨先看看下面这张图,看到下图中的网络,你想把它分成几个社区呢?怎么分,每个节点属于哪一个社区呢?
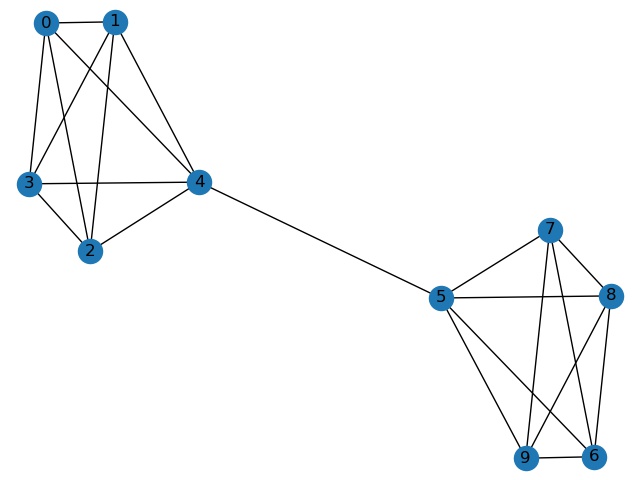
我相信,绝大多数人的第一感觉都是把这个网络分成左右 2 个社区,其中[0,1,2,3,4]节点属于第 1 个社区,而[5,6,7,8,9]节点属于第 2 个社区(当然,社区的顺序可以随意)。
为什么会有这样的第一感觉呢?虽然有很多种可能,但我们可以合理地怀疑跟边的密集程度有关。设想在学校中,同一个班级的学生,互为微信好友的可能性很高,甚至可能是完全图,即每个同学都与同班所有其他同学互为微信好友,而两个学生在分别属于两个不同班级的情况下,他们互为微信好友的可能性就比较低了。也就是说,假如我们划分出一个点集,这个点集的边的密度非常高,那么这个点集就应该能划分成一个社区。
那么,如何来衡量一个点集的边的密度?直接用边的数量除以点的数量吗,可能是其中一种方法,但仔细想想却并不合理。这里就不再卖关子了,我们直接引出我们的 modularity(模块度) 的概念。在对网络进行某个社区划分之后,模块度就可以用于测量这样划分得好不好,也可以理解为用于测量社区内的边的密度高不高。
Modularity 模块度
Modularity(模块度), 这个概念是2003年一个叫Newman的人提出的。这个人先后发表了很多关于社区划分的论文,包括2002年发表的著名的Girvan-Newman(G-N)算法,和2004发表的Fast Newman(F-B)算法,Modularity就是F-B算法中提出的(03年提出的概念,04年确认发表)。
在2006年的时候Newman重新定义了Modularity,实际上只是对原来的公式做了变换,使其适用于Spectral Optimization Algorithms。
早期的算法不能够很好的确认什么样的社区划分是最优的。Modularity这个概念就是为了定义一个对于社区划分结果优劣的评判。
接下来,我们以一种相对抽象的想法来理解模块度。假如一个网络,考虑它的某一个点集,点集里面的每一个点都与该点集里面的其他点有较多的边相连,而与其他点集的点只有较少的边相连,那么这些点的边是不均匀分布的。点集中某个点的邻边,有更大的概率与点集内的点相邻,这可以看作是社区的一种“特征”。
那么这种不均匀的分布会导致什么呢?我们来考虑一种叫 “平均图” 的东西,它的点的邻边的分布是比较均匀,这种图的点与点之间一视同仁,并不存在明显小团体。那么,当我们用原来的不均匀分布的网络,减去这种“平均图”,那么边比较密集的那些区域就会体现出来。这样的说法有点抽象,可以慢慢理解。
于是,我们现在就产生了一种方法,去求得这个“平均图”。如果使用正则图就有点太过离谱了,毕竟我们只在意每个点的邻边的分布,而并不需要改变每个点的度数(邻边的数量)。所以,我们可以通过点的度数来计算边权,从而在得到“平均图”的同时,保证邻边的期望值(边权的和)与原来的网络相等。
所以,我们现在可以把“平均图”称作期望图。假设在原来的网络中,有 m 条边,则总度数为 2m,有任意两个节点 i 和 j (允许i=j),它们的度数分别为 $k_i$ 和 $k_j$,那么在期望图中,节点 i 和 j 相邻边的边权就为 $\frac{k_ik_j}{2m}$。用数学表达就是:
$$e(i,j)_{i\in N,j\in N}=\frac{k_ik_j}{2m}$$
其中 N 为网络所有点的集合,m 为边数。
请记住,期望图和原网络的点都是一样的,不同的只是边权而已。像上面的式子,这样的设计有非常巧妙的地方,让我们来算一算每个点的度数的期望(边权之和):
$$E(i)=\sum_{j\in N}e(i,j)=\sum_{j\in N}\frac{k_ik_j}{2m}=\frac{k_i}{2m}\sum_{j\in N}k_j=\frac{k_i}{2m}\cdot 2m=k_i$$
可以看到,在期望图中,任意一个节点 i 的邻边的边权之和为 $k_i$,而 $k_i$ 恰好又等于原网络的节点 i 的度数。这样设计,相当于没有改变每个点的邻边的数量,而是把邻边相对均匀地分到其他每一个点。并且,整个图的总度数也没有改变(对上式进行求和即可)。求期望图的代码也非常简单,示例如下(python):
# 各顶点的度数
d = np.sum(A, axis = 0)
# 边数,即总度数的一半
m = np.sum(d) / 2
# 用度数求出期望图
B = np.array([d]).T @ np.array([d]) / (m * 2)下一步,我们用原网络减去期望图。原网络的两点之间如果有边相连,则可以把边权看作是 1,如果两点之间没有边,则可以看作有边且边权为 0。而期望图中,任意两点之间的边权都可以用上式计算得到,于是将原网络的每一条边的边权减去期望图的对应边的边权。不难想到,这样得到的新网络中,边是有负权的,不妨思考一下哪些边是负权。
因为网络中存在隐式的社区,社区内的边比较密集,而不同社区之间的边比较稀疏,所以在减去期望图之后,社区内的边的边权很有可能还是正数,而不同社区之间的边的边权可能就变成了正数。那么此时有一个很朴素的想法就是,尽量去找那些边权为正数的边。
我们前面说过,模块度 modularity 用来评估某个社区检测的效果,它是从已有的社区检测算出某个值。那么假设我们现在手上有原网络减去期望图之后的边权,有正有负,而且已把所有点划分为若干个社区,那么我们只统计在社区内的边。也就是说,我们只对其中一部分的边进行求和,这些边所连接的两个节点都在同一个社区内。假如划分得非常好,使得社区内的边尽可能的密集,社区之间的边尽可能的稀疏,那么求和时就会保留那些社区内的正权边,同时丢弃社区之间的负权边,于是最后得到的值就会比较大。数学表达如下:
$$Q(G,S)=\frac{1}{2m}\sum_{s\in S}\sum_{i\in s}\sum_{j\in s}(G_{ij}-\frac{k_ik_j}{2m})$$
其中,$G$ 是图的邻接矩阵,保存了边的信息,$G_{ij}$ 即为点 i 和点 j 之间的边权(相连即为1,否则为0);$S$ 是对图的一个划分,把所有点划分为若干个子集;$k_i$ 是点 i 的度数;$m$ 是图的总边数,$2m$ 就是总度数。式子右边的 $\sum_{s\in S}$ 表示依次取出划分的一个子集,然后统计那些两个端点都在子集内的边(包括自环)。最后乘上 $\frac{1}{2m}$ 用于归一化,由于图的总度数为 $2m$,期望图的总度数不变,也是 $2m$,那么减去期望图之后,取部分边进行求和,最终所得到的结果的取指范围就是 [-2m, 2m],乘上 $\frac{1}{2m}$ 后就能把取指范围限制到 [-1, 1]。所以模块度的取值范围是 [-1, 1],一般来说,当模块度在 [0.3, 0.7] 区间内时,我们认为实现了一个较好的社区划分,这是实践所总结的经验。
Modularity 的 python 实现
前面介绍了模块度的计算方法,其实按照公式的概念很简单就能用代码来实现。但我们可以通过矩阵相乘的形式去简化它,注意我说的是简化而不是优化,用矩阵相乘来计算模块度并不会降低时间复杂度。
我们考虑下面这张图:

只有 3 个节点 A、B、C 和 2 条边 AB、AC,那么它的邻接矩阵可以简单地像这样表示:
$$ \left[ \begin{array}{ccc} 0&1&1 \\ 1&0&0 \\ 1&0&0 \end{array} \right] $$
现在假设我们划分两个社区,把节点 A 和 C 划分到 1 个社区,节点 B 单独划分到另 1 个社区。我们前面说过,模块度只统计社区内的边,于是我们可以一个一个社区地进行统计,我们不妨来看 A 和 C 组成的社区。
在邻接矩阵中,A 和 C 组成的社区里的边如下所示:

矩阵中黄色位置的元素就是我们要统计的元素,换句话说,我们计算这个社区时,要把矩阵中那些位置的元素抽出来求和。我们不妨来看下面的运算:
$$ \left[ \begin{array}{ccc} 1&0&1 \end{array} \right] \cdot \left[ \begin{array}{ccc} 0&1&1 \\ 1&0&0 \\ 1&0&0 \end{array} \right] \cdot \left[ \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \right]=2 $$
我们只需要在邻接矩阵左右分别乘上一个相同的向量,就可以提取出想要的元素,如果看不懂可以再看下面的一般形式:
$$ \left[ \begin{array}{ccc} 1&0&1 \end{array} \right] \cdot \left[ \begin{array}{ccc} a&b&c \\ d&e&f \\ g&h&i \end{array} \right] \cdot \left[ \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \right]= \left[ \begin{array}{ccc} a+g&b+h&c+i \end{array} \right] \cdot \left[ \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \right]=a+c+g+i $$
请以自己的线性代数知识感受一下,这两个向量就像掩码,分别从水平方向和竖直方向对邻接矩阵的元素进行过滤,只留下社区内的边进行求和。因为我们现在是以 A 和 C 为一个社区,进行求和,所以向量是 [1 0 1],如果我们是以 B 为一个社区进行求和,那么向量就是 [0 1 0],也就是说,社区内有哪些点,我们就把对应位置设为 1。那么假如我们想同时求这两个社区的元素,那么可以把这些向量并起来一起算,比如下面这样:
$$ \left[ \begin{array}{ccc} 1&0&1 \\ 0&1&0 \end{array} \right] \cdot \left[ \begin{array}{ccc} 0&1&1 \\ 1&0&0 \\ 1&0&0 \end{array} \right] \cdot \left[ \begin{array}{c} 1&0 \\ 0&1 \\ 1&0 \end{array} \right]= \left[ \begin{array}{c} 2&1 \\ 1&0 \end{array} \right] $$
其中,最终结果所得到的矩阵的对角线就是每一个社区的边权之和(每一条边要算两遍),所以,我们使用矩阵的迹来得到对角线上的和,就等于模块度。所以我们可以完全使用矩阵运算的方式来求得模块度,这在 python 中能极大地压缩代码量,所以最后我们求模块度的代码如下:
# 计算图的模块度,输入为图的邻接矩阵A和社区数组community
def modularity(A, community):
# 各顶点的度数
d = np.sum(A, axis = 0)
# 边数,即总度数的一半
m = np.sum(d) / 2
# 社区矩阵,若第i个节点归属于第j个社区,则矩阵第i行第j列为1,其他为0
S = np.zeros(A.shape, dtype=int)
for i in range(0, A.shape[0]):
S[i][community[i]] = 1
# 用度数求出随机期望的图,再用原图的邻接矩阵减去那个图
B = A - (np.array([d]).T @ np.array([d]) / (m * 2))
# 返回模块度
return np.trace(S.T @ B @ S) / (m * 2)Louvain 算法
Louvain 算法,原文是 Fast unfolding of communities in large networks。
虽然我们知道如何用模块度来评价社区划分的好坏,但我们目标还是想要获得一个效果较好的社区检测。那么思路就很简单,我们只需要想办法去改变社区的划分,使得模块度的值增大,那就能不断优化社区检测。这就像机器学习中,我们使用梯度下降的方法去改变模型使得 $Loss$ 函数的值降低。
Louvain 算法的思路很简单,它是一个贪心算法。就是一直尝试改变点所属的社区,如果改变能使模块度增大,那就改变;如果不能使模块度增大,那就不变。
Louvain 算法用于求出不同层次的社区,它总共分两部分,但我们可以先单看它的第一部分:
在初始化时,每一个点自己都是一个独立的社区,有 N 个点就有 N 个社区
然后不断循环遍历每一个点:(遍历到最后一个点就再从第一个点开始)对于第i个点,遍历与它相邻的所有点:
当遍历到第i个点的第j个邻居时,尝试把i点脱离原来的社区,加入邻居所在的社区,然后计算模块度。
如果i点换社区之后,模块度相比原来的有所提升,那么i点就留在新社区(贪心);反之如果模块度没提升,i点就返回原来的社区。假如所有的点无论怎么改变它们所在的社区,都无法提升模块度时,那么停止迭代,算法完成。这样就知道了每个点所属的社区,也就得到了一个社区划分。
所以第一部分就是一个非常简单的贪心思路:能增就改。它的输入就是图的邻接矩阵,输出就是对这个图的划分,它的 python 代码实现如下,相关注释已经表明,非常清晰易懂:
# Louvain算法的第一步,将图G的节点聚到多个社区
def first_phase(G):
community = np.arange(G.shape[0]) # 社区数组,记录每个节点所属社区的下标
# 记录上一次改变社区的节点,如果遍历了一轮都没有节点改变自己的社区,那么算法收敛,结束循环
last_i = G.shape[0] - 1
max_modularity = modularity(G, community)
i = 0
cnt = 0 # 统计迭代次数
while True:
s_i = community[i] # 记录节点i原来的社区
flag = False # 遍历节点i之后,节点i的社区是否发生改变
# 遍历第i个节点的所有邻居,尝试加入邻居的社区,选择能够使模块度增最多的那个社区
for j in range(0, G.shape[0]):
if G[i][j] == 1:
community[i] = community[j] # 节点i加入新的社区
next_modularity = modularity(G, community) # 计算新的模块度
community[i] = s_i # 节点i返回原来的社区
# 如果改变节点i的社区能使模块度变大,那就直接变过去
if next_modularity > max_modularity:
max_modularity = next_modularity
s_i = community[i] = community[j]
flag = True
if last_i == i and flag == False: #如果所有的点跑完一轮都没变过,那么就结束循环
break
if flag == True:
last_i = i
i = (i + 1) % G.shape[0] # 循环遍历节点
cnt += 1
print("遍历次数: ", cnt)
# 利用桶排序,将社区的标签映射到01234...
b = np.zeros(len(community), dtype=int)
for i in range(0, len(community)):
b[community[i]] += 1
labels = np.zeros(len(community), dtype=int)
num = 0
for i in range(0, len(community)):
if b[i] > 0:
labels[community[i]] = num
num += 1
for i in range(0, len(community)):
community[i] = labels[community[i]]
return community显然,Louvain 算法的第一部分注重的是个体改变对模块度的影响,那么自然而然地可以想到,多个点同时改变社区也能对模块度产生影响。所以,Louvain 算法的第二部分就很朴素,把社区合并成一个点,也就是纯粹地压缩。
Louvain 算法的第一部分把所有点划分成多个社区,社区内有边,社区之间也有边。Louvain 算法的第二部分就是把这些社区分别合成一个点,原来的社区内部的边权加起来作为点的自环的边权,原来的社区与社区之间的边权也加起来作为点与点之间的边。就像下图所示:
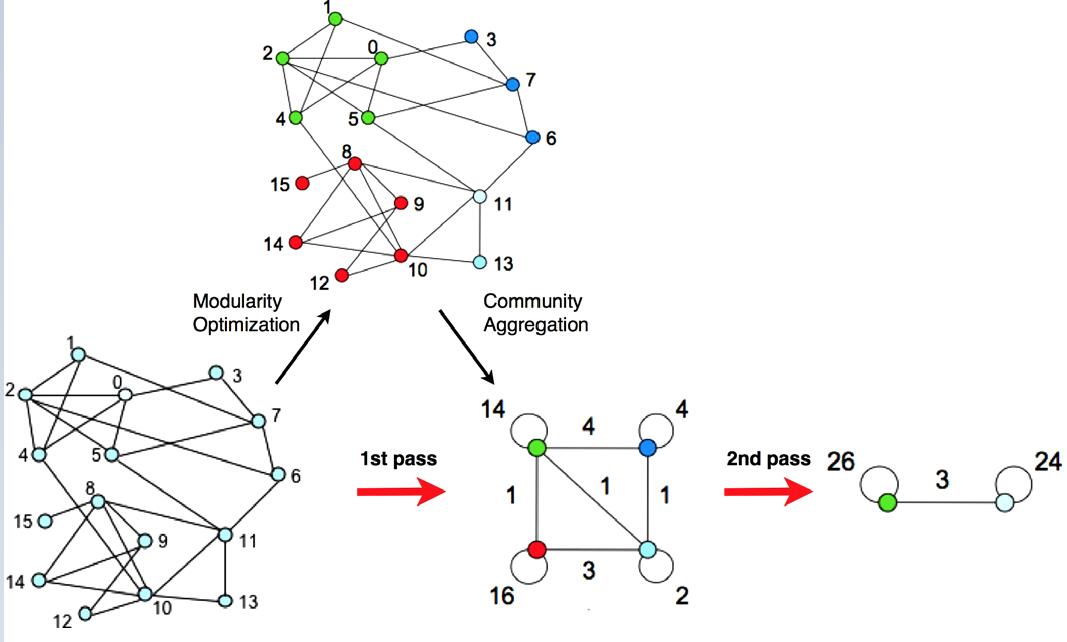
在上图中,Modularity Optimization 就是 Louvain 算法的第一部分,Community Aggregation 就是第二部分。两个部分合起来叫做一个 pass。第二部分的代码实现如下:
# Louvain算法的第二步,将社区合成一个节点
def second_phase(G, community):
n = max(community) + 1
A = np.zeros((n, n))
## 直接将原来的边权加到新图的边
for i in range(0, G.shape[0]):
for j in range(0, G.shape[1]):
A[community[i]][community[j]] += G[i][j]
return A在经过了第二部分之后,整个图的规模就变小了,就要重新进行第一部分的计算。我们前面说过,第一部分关注的是单个点的改变对模块度产生的影响,并没有考虑一群点的改变。而第二部分把社区合成点之后,再丢进第一部分的运算中,我们就可以把整个社区看成一个整体,试图把一整个社区加入到另一个社区中,观察对模块度产生什么影响,假如模块度还能增大,那么就说明在原来的网络中,把两个社区合并是更明智的选择。
所以,整个 Louvain 算法就是不断地重复第一部分和第二部分,直到模块度无法再增大为止(假如第一部分的输入是N个点,输出还有N个社区,那么说明任何点都不需改变,整个 Louvain 算法就停止)。 python 代码如下:
# Louvain 算法,输入为图的邻接矩阵,输出为图的最优社区划分
def Louvain(G):
# 社区数组,记录每个节点所属社区的下标
community = np.arange(G.shape[0])
print(modularity(G, community))
while True: # 不断进行两部分
next_community = first_phase(G) # 第一部分,划分
if np.max(next_community) + 1 == len(next_community):
# 如果输入N个点,划分后还是N个社区,算法停止
break
print(next_community)
print(modularity(G, next_community))
# 经过第一部分之后,要更新原图的社区标签
for i in range(0, len(community)):
community[i] = next_community[community[i]]
G = second_phase(G, next_community) # 第二部分,压缩
return community实验对比
下面我们来找若干个数据集进行测试。这一次所需的数据集跟一般的数据集有点不同,这次我们是在网络上进行操作的,需要知道点和边,用数据集构建图的信息。我从 http://www-personal.umich.edu/~mejn/netdata/ 下载数据集进行测试,里面的数据集都是 .gml 的文件格式,在 python 中我们可以用 networkx 库来处理这种文件,只需要先安装即可:
pip install networkx本篇中,我们自己实现的代码都是用邻接矩阵来表示图,所以需要知道从 .gml 文件获得图的邻接矩阵,方法也很简单,像下面这样即可:
import networkx as nx
# 从数据集中读入图
gml = nx.read_gml("./football.gml", label='id')
# 获得原始图的邻接矩阵
G = np.array(nx.adjacency_matrix(gml).todense())当然,我们还需要将自己实现社区划分的效果与一般的函数接口作对比,在 中有通用的 Louvain 算法的接口,那么我们以同样的方式安装该库即可:
pip install python-louvainpython-louvain 库恰好跟 networkx 库一起使用,只需要像下面这样,就能把从 .gml 文件中读到的图使用官方接口进行社区检测,得到的就是每个点的社区标签,用于我们后面作对比。
import networkx as nx
from community import community_louvain
gml = nx.read_gml("./football.gml", label='id')
# 通过官方接口进行社区划分,
partition = community_louvain.best_partition(gml)对于每一个数据集,我们手上有自己实现的 Louvain 算法所得到的社区标签、调用函数接口得到的社区标签,还可能有数据集上自带的真实的社区标签。我们既可以用一份标签来计算 modularity 模块度,也可以用两份标签来计算 NMI 标准化互信息,实验结果如下:
(含有真实分类的数据集真的太难找了,几乎只有一个 football.gml 是用得舒服的)
| 数据集 | A模块度 | B模块度 | C模块度 | NMI(A,B) | NMI(A,C) | NMI(B,C) |
|---|---|---|---|---|---|---|
| football.gml | 0.553973318714 | 0.593152974300 | 0.478151470717 | 0.898841957085 | 0.702360550597 | 0.710891868390 |
| polbooks.gml | 0.414940276942 | 0.4845511900905 | 0.393879093587 | 0.421681674833 | 0.3540086425180 | 0.483870408489 |
| adjnoun.gml | -0.2419266435986 | 0.2034103806228 | 0.24391695501 | 0.00308767441261 | 0.00704978959959 | 0.4346447199389 |
| karate.gml | noun | 0.361357659434 | 0.293885601577 | noun | noun | 0.479548636089 |
| lesmis.gml | noun | 0.532643065286 | 0.2591527683055 | noun | noun | 0.492993980138 |
A代表数据集自带的真实社区划分,B代表本篇手动实现的社区划分,C代表函数接口的通用社区划分。
可以看到,在正常的数据集中(比如前两个),我们实现的 Louvain 算法表现出了较好的效果,模块度是三者最高,与真实社区划分的 NMI 甚至超过了用接口计算的社区检测,这令我非常吃惊,可能是咱们写得太好了?另外要提一下第三个数据集 adjnoun.gml,它非常得特别,它是列出了文本中出现的形容词和名词,把这些词作为节点,如果形容词和名词连在一起出现,那么在这两个词的节点之间连上一条边,所以在这个数据集中,有边相连的两个点反而是不同类别的,而我们的社区检测更多是把有边相连的点看作同一类别,所以该数据集的性质跟我们的算法是反过来的,因此,可以看到那一行的各个数据都非常小。
总的来说,我们实现的算法是很成功的。能较好地检测出网络中隐藏的社区,效果甚至比接口要好。
心得体会
这次的算法非常好玩,它的思想和实现都很简单,却能实现很神奇的效果。而且,像模块度这样东西,我觉得它很像那些数模比赛的产物。当初打数模比赛的时候,就是针对一个问题,自己构建个奇奇怪怪的模型去评估它。这个模块度也是,虽然整体思想看似很合理,但一切的构造都有点太巧合了,包括用度数求出期望边权、相减、逐社区求和,这些操作让我觉得它是那种先有公式后有理论的东西。就是那种,大家奇思妙想发明了很多公式,然后发现某一个公式的效果还不错,就共同决定使用那个公式,并给它编出合理的推论。无论怎么说,发明出这些算法的人还是很聪明的,善于从问题中抽象出数学模型,我在用代码实现时也感受到了快乐。